The Pennsylvania State University, Spring 2021 Stat 415-001, Hyebin Song
Point Estimation
Point EstimationIntroduction to Point EstimationLearning objectivesRecapThe bias and mean squared error of point estimatorsMethod of Moments EstimationLearning objectivesProcedures to obtain Method of Moments (MoM) estimators of Maximum Likelihood EstimationLearning objectivesProcedures to obtain Maximum Likelihood Estimators (MLE) of Properties of Point EstimatorsLearning objectivesFinite sample propertiesLarge sample (asymptotic) propertiesProperties of MoM estimatorsProperties of MLEsSufficient Statistics and Rao-BlackwellizationLearning ObjectivesSufficient statistics and the factorization theoremRao-Blackwellization
Introduction to Point Estimation
Learning objectives
- Understand the goal of point estimation
- Understand bias and mean square error of point estimators
Recap
Setting: , i.i.d., where is an unknown value in the parameter space .
- we have a sample where is independent and identically distributed (i.i.d), and the distribution of is known up to an unknown parameter value. That is, we know that the distribution function of is in the collection of distribution functions , but we do not know which one because we do not know the value of .
- the goal is to choose a "plausible" in based on the sample .
Recall the definitions:
- A point estimator of :
- A point estimate of :
Notation:
Recall that for a continuous random variable with a pdf , the probability of an event , the expectation of , and the variance of are computed as
Note: for a discrete random variable , we can replace the pdf with a pmf and the integrations with summations.
We sometimes use subscripts and write , and to emphasize that the expectation and variance are computed using a pdf with a particular value of .
The bias and mean squared error of point estimators
Definition (Biased and unbiased estimators)
- If ) for all , then is unbiased. Otherwise, the estimator is biased.
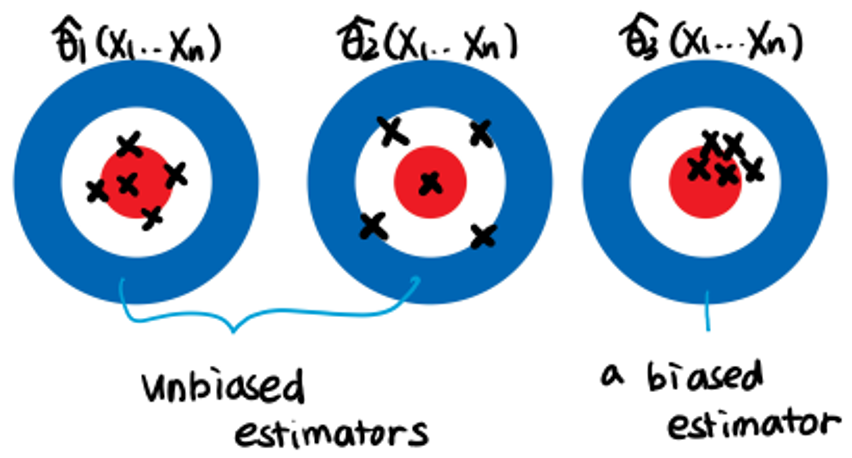
Example Suppose we have , i.i.d. where the parameter space . We consider the following three two estimators
Are three estimators unbiased?
For any ,
- we have . Therefore is an unbiased estimator of .
- . Therefore is an unbiased estimator of .
- Therefore is not an unbiased estimator of .
Mean Squared Error (MSE)
Definition:
MSE captures both bias and variance
Proof.
In particular, if an estimator is unbiased, .
Example (cont'd) Compute MSE of .
Method of Moments Estimation
Learning objectives
- Understand how to compute method of moments estimators
Setting: , i,i,d., where is an unknown value in the parameter space .
- Recall the th (population) moment of is defined as .
- Define the th (sample) moment of a sample as
Idea: Substitution principle
- From the WLLN, we know for
- If , then
Example. , i,i,d. We want to estimate .
. .
Procedures to obtain Method of Moments (MoM) estimators of
- Write as functions of .
- Solve (1) with respect to . That is, find such that
- Substituted population moments with sample moments
Example , i,i,d. We want to estimate .
Write as functions of .
.
Solve 1 with respect to .
- .
Substitute population moments with sample moments
Therefore,
Remark: The Method of Moments estimator for is unbiased, but the Method of Moments estimator for is biased
Maximum Likelihood Estimation
Learning objectives
Understand how to compute maximum likelihood estimators (MLE)
Understand invariance property of MLE
Setting: , i,i,d., where is an unknown value in the parameter space .
Idea: Choose the value of that is most likely to have given rise to the observed data
Example: Suppose . We have the observed sample . Suppose the parameter space (so the parameter space contains only 2 values).
Given each , what is the probability of observing ?
- when ,
- when ,
Thus, since , is the maximum likelihood estimate of .
Remark:
- For any , is a function of .
- Finding a maximum likelihood estimate can be viewed as finding a maximizer of the function for .
- We call the likelihood function.
Definition (Likelihood function)
- The likelihood function of based on the observed values from a random sample with pmf or pdf is
- The log likelihood function of is .
Definition (Maximum Likelihood Estimator)
The maximum likelihood estimate is a value which maximizes the likelihood function . In other words,
such that
, for any .
The maximum likelihood estimator is .
Since is a strictly increasing function, the maximizer of the likelihood is the same as the maximizer of the log-likelihood . Maximizing the log-likelihood is often easier.
Example. Likelihood and log-likelihood function of based on the observed sample , when i.i.d., .
.
Therefore,
Procedures to obtain Maximum Likelihood Estimators (MLE) of
Compute the log-likelihood function
- Find the pdf or pmf of
- Find the log-likelihood function
Find a maximizer of the log-likelihood function
Compute stationary points of the log-likelihood.
- When the likelihood is differentiable (most cases), find the solution of the equation inside the parameter space.
Find a maximizer among candidate points (stationary points and boundary points).
For a given sample , the maximum likelihood estimate is . The maximum likelihood estimator is , which is a random variable.
Example (Bernoulli MLE) Compute the MLE of for a sample , when i.i.d., .
- a. Find stationary points in .
Solving for , we get the solution of .
When , is the unique stationary point in .
When or , there exist no stationary points in .
b. When , is the global maximizer, since
, for , and
.
When or ,
and it is straightforward to verify that both functions are monotone and the maximum achieves at and . Then again, is the global maximizer.
Therefore, the maximum likelihood estimate of : .
- The maximum likelihood estimator of : .
Example (Normal MLE, both and unknown) Compute the MLE of for a sample , when i.i.d.,
We have
a. pdf of :
b. Log-likelihood
a. Find stationary points in
we get , .
b. we can verify the solution in a is indeed the unique global maximizer by using a second derivative condition (positive determinant and negative first element of the hessian matrix) and checking that there is no maximum at infinity.
- The maximum likelihood estimator
Example (Uniform MLE) Compute the MLE of for a sample , when i.i.d., .
a. pdf of :
Joint pdf of :
b. Likelihood:
Log-likelihood:
a. Find stationary points in .
For ,
. No stationary points exist. The log-likelihood is a decreasing function of .
Therefore, the log-likelihood function is maximized at .
The maximum likelihood estimator .
Theorem (Invariance) If is the MLE of , then for any function , is the MLE of .
Remark Theorem 6.4-1 in HTZ requires that is one-to-one. When is not one-to-one, the discussion becomes more subtle, but we will not worry about this point in this class.
Proof (when is one-to-one)
Let . We have that is the maximizer of .
This function has the largest value .
Therefore, is the maximizer of the function .
Example (Bernoulli MLE) Compute the MLE of for a sample , when i.i.d., .
The parameter of interest .
Since the MLE of is , the MLE of is .
Properties of Point Estimators
Learning objectives
- Understand various finite sample (unbiasedness, sufficiency) and large properties (consistency, asymptotic normality/efficiency) of point estimators
- Understand optimal properties of maximum likelihood estimators
Finite sample properties
Unbiasedness
- is an unbiased estimator if ) for all .
Example: for a sample , when , i.i.d., we consider two estimators for , and .
For , . Similarly, .
Both are unbiased.
Among unbiased estimators and , which estimator should we use?
Relative Efficiency
- Definition: Given two unbiased estimators and of a parameter , the efficiency of relative to , denoted by , is defined to be the ratio
is more efficient than iff . Obviously, given any two unbiased estimators, we would prefer a more efficient estimator.
Pushing this idea even further, we may consider the "best" unbiased estimator, which we define in the following way.
Example: for a sample , when , i.i.d., we consider two estimators and for .
is more efficient than .
Definition (Minimum Variance Unbiased Estimator (MVUE)) An estimator is a best unbiased estimator of if is unbiased (i.e., , for all ), and has a minimum variance (i.e., for any other unbiased estimator , , for all .)
Finding a best unbiased estimator (if it exists!) is not an easy task for a variety of reasons. One obvious challenge is that we cannot check the variances of all unbiased estimators. The following theorem provides a lower bound on the variance of any unbiased estimator of . That is, if we find an unbiased estimator for which the variance matches with the lower bound, then we know that we have found the MVUE.
- Theorem (Cramer-Rao Inequality) , i,i,d. with pdf (or pmf) . Let be any unbiased estimator of . Under very general conditions,
- We define the efficiency of an unbiased estimator of as
We say an unbiased estimator is efficient if , i.e., the variance of equals the Cramer-Rao lower bound .
Example: Let be a random sample from a Poisson distribution with parameter . Determine the Cramer-Rao lower bound.
Therefore, the Cramer-Rao lower bound is .
We note . Therefore, the efficiency of is , i.e., is efficient.
Sufficiency
- A statistic is said to be sufficient for a parameter if the statistic captures all the information in a sample about a target parameter (the formal definition will be presented later).
- Sufficient statistics are not unique. In fact, the random sample itself is a sufficient statistic. We would like to find a sufficient statistic that reduces the data in the sample as much as possible. Such a statistic is called minimal sufficient.
- Often, "good" estimators are functions of a minimal sufficient statistic.
Large sample (asymptotic) properties
Consistency: If , then is a consistent estimator.
Remark: consistency is often considered as a "minimum requirement" an estimator should meet.
Theorem If , then is consistent.
proof. For any , .
Example: for a random sample , when , is a consistent estimator of ? How about ?
By WLLN, .
Or, . Thus is a consistent estimator of .
We have . Let be any positive number. We have,
Therefore, is not a consistent estimator of .
Asymptotic Normality: we say an estimator is asymptotically normal if the distribution of when is large.
The distribution of when is large is called an asymptotic distribution of . An estimator is asymptotically normal if its asymptotic distribution is Normal, and we denote it as
Example: for a random sample , when , is an asymptotically normal estimator of ?
by CLT. Thus is an asymptotically normal estimator of .
Asymptotic Efficiency: we say an asymptotically normal estimator is asymptotically efficient if coincides with the Cramer-Rao Lower bound .
Example: for a random sample , when , is an asymptotically efficient estimator of ?
We have,
. Now we compute the C-R lower bound.
We have, , and
.
Therefore, .
Since , is an asymptotically efficient estimator.
Properties of MoM estimators
- In most practical cases, MoM estimators are consistent.
- Not necessarily unbiased.
- Often, MoM estimators are not minimal sufficient, and a "better" estimator can be found.
Properties of MLEs
Theorem (asymptotic optimality of the MLE) Under some regularity conditions, an MLE is consistent, asymptotically normal, and asymptotically efficient. In other words, when is large,
- In most cases, an MLE is minimal sufficient.
Sufficient Statistics and Rao-Blackwellization
Learning Objectives
Understand the concept of sufficient statistics
Understand how to find sufficient statistics
Understand how we can improve an unbiased estimator using the Rao-Blackwell theorem.
Sufficient statistics and the factorization theorem
Definition (Sufficient Statistics) Let be a random sample from a probability distribution with unknown parameter . Then the statistic is said to be sufficient for if the conditional distribution of given does not depend on .
Remark: In words, sufficiency of for means that given the value of , "extra variability" in the sample , in addition to that already contained in , does not depend on the parameter . Therefore, given the sufficient statistic , we do not need to look at other functions of , since we cannot gain any further information about the parameter.
Example Suppose we have a random sample , when . Show is sufficient for .
Compute the conditional pdf
This definition tells us how to check whether a statistic is sufficient, but it does not tell us how to find a sufficient statistic. The following theorem is very useful in the search for a sufficient statistic.
Theorem (Factorization Theorem) Let denote random variables with joint pdf or pmf , which depends on the parameter . The statistic is sufficient for if and only if
where depends on only through and does not depend on .
Theorem (Factorization Theorem for two parameters) Let denote random variables with joint pdf or pmf , which depends on the parameter . The statistics , are (jointly) sufficient for if and only if
where depends on only through and , and does not depend on .
Example (one parameter): Let be a random sample from a Poisson distribution with parameter . Show is sufficient for .
Therefore, is sufficient for .
Example (two parameters): Let be a random sample from a Normal distribution with parameter . Show () are (jointly) sufficient for .
Therefore () are (jointly) sufficient for .
Theorem (Sufficient Statistic when a pmf/pdf is of the exponential form) Let be a random sample from a distribution with a pdf or pmf of the form
on a support free of . Then the statistic is sufficient for .
Proof. Factorization theorem.
Remark 1 Many of familiar distributions (Binomial, Poisson, Normal, Exponential, etc.) have a pmf or pdf which is of the exponential form. A noteworthy exception is uniform distribution, where the support depends on .
For .
Remark 2 In fact, is minimal sufficient for .
Example: Let be a random sample from a Poisson distribution with parameter . Show is sufficient for .
Therefore , and is sufficient for .
Rao-Blackwellization
Previously, we mentioned that a "good" estimator should be based on a sufficient statistic because a sufficient statistic contains all information about a parameter. In other words, given a sufficient statistic, adding another statistic (i.e., a function of ) only introduces noise, because there is no information left in the conditional distribution of .
In fact, if we have an unbiased estimator which is not based on a sufficient statistic, we can improve the estimator based on the sufficient statistic.
Theorem (Rao-Blackwell Theorem) Let be a random sample from a distribution with pdf or pmf . Let be an unbiased estimator of . Let be a sufficient statistic for , and . Then,
- is a function of the sufficient statistic , where the function does not depend on . In particular, a statistic.
- .
- , where the inequality is strict if the original estimator was not a function of alone.
Remark 1 the new estimator , which is based on the sufficient statistic , is a better estimator than the original estimator if the original estimator was not a function of alone.
Remark 2 In many cases, by improving an estimator based on the Rao-Blackwell theorem (called Rao-Blackwellization), we not only get an estimator with a smaller variance but we actually obtain a minimum-variance unbiased estimator (MVUE). This is especially true when we use a sufficient statistic from the previous theorem (Sufficient Statistic when a pmf/pdf is of the exponential form).